攻防世界 MISC
流量分析题
traffic
拿到手,检查下包的大小,没几个想着慢慢追踪流,也能找到,后面发现方向错了
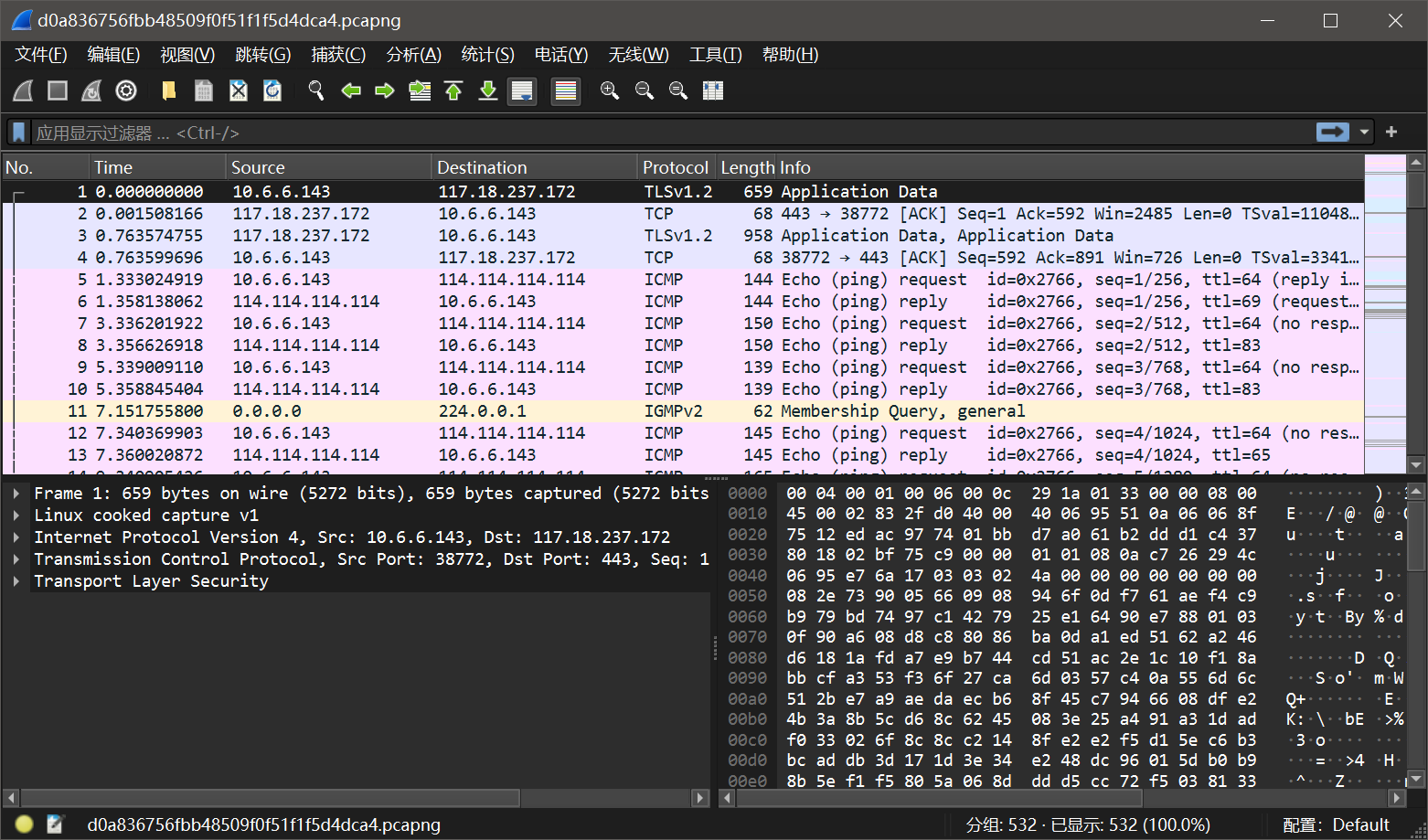
看了其他师傅的解题思路,从icmp包的大小下手
不过wireshark图形化不能批量导出包大小
但是可以通过tshark命令行工具来到处icmp包的大小
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
- -r指定要分析的PCAP文件为d0a836756fbb48509f0f51f1f5d4dca4.pcapng。
- -Y指定过滤条件为icmp,即只显示与ICMP协议相关的数据包。
- -T指定输出格式为fields,即只输出指定的字段。
- -e指定要输出的字段为frame.len,即数据包的长度
- uniq 去重
- tr 将换行符替换为逗号
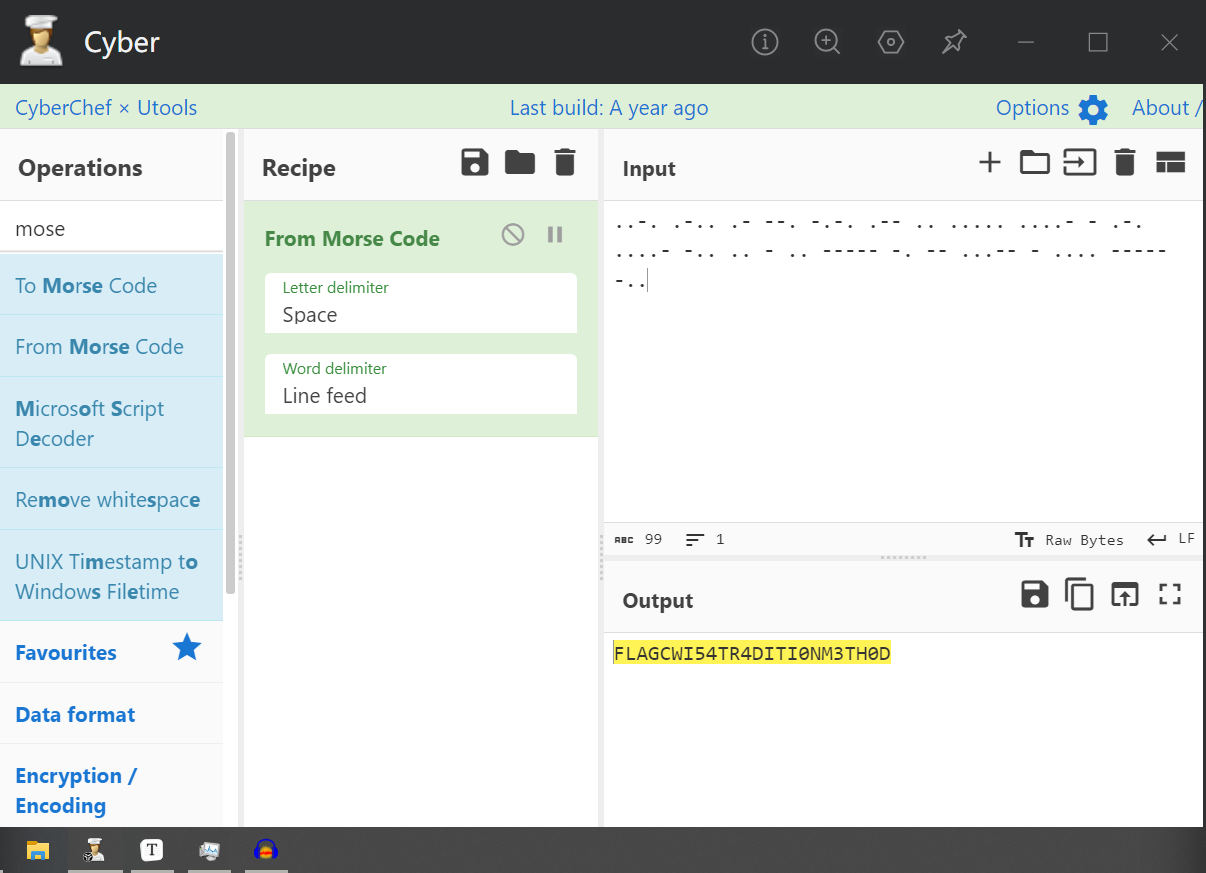
得到这个十进制利用python的chr方法转化为ASCII字符
1 | a = [144,150,139,145,165,91,109,151,122,113,106,119,93,167] |
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
好吧,尝试使用遍历ASCII表中的其他字符
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
其实还可以再优化下,直接在python中加个if语句就行,不过答案已经出来了就懒得加了
奇怪的TTL字段
图片隐写题
拿到手是个TTL值很长,给了提示
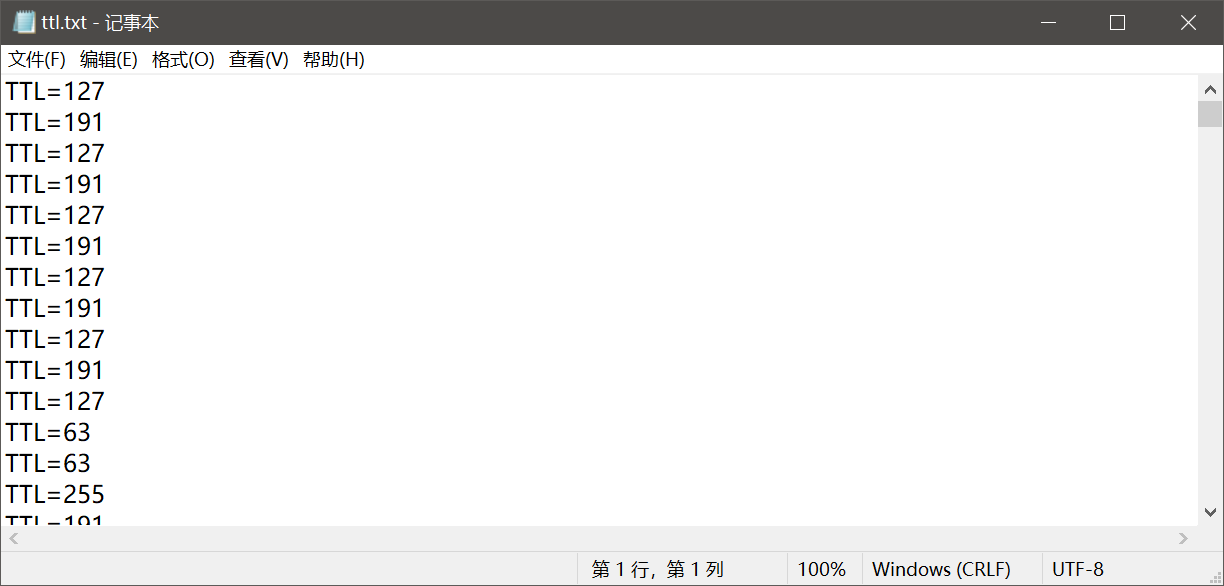
我们截获了一些IP数据报,发现报文头中的TTL值特别可疑,怀疑是通信方嵌入了数据到TTL,我们将这些TTL值提取了出来,你能看出什么端倪吗?
其实刚开始也没啥思路,后面看了下,好多都是重复的,像127,191,63,255,这些数字
然而发现有个规律这些数字的二进制位为xx111111,都是2的6+N次方-1,这样就很可疑了
尝试利用sed提取出TTL=后面的值,接着使用tr去掉回车,bc转为二进制
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads/Compressed/0bf565e00b864f4ba06efc858056c7e9] |
- head: 用于显示文件的开头部分,默认显示文件的前10行内容。
- ttl: 参数指定要显示的行数,如ttl=20表示显示文件的前20行内容。
- tr -d “\r”: tr是一个用于对文本进行转换或删除的命令。-d选项指定删除字符,”\r”表示删除回车符。这里的作用是删除文件中的回车符。
- xargs -I {}: xargs命令用于将标准输入转换为命令行参数。-I选项指定用{}表示xargs传递的参数。这里的作用是将命令行参数{}传递给后面的命令。
- echo “obase=2; {}”: echo命令用于输出内容到标准输出,这里输出的内容是将参数{}作为输入给bc命令进行二进制输出。
- bc: bc是一个用于数学计算的程序,具有计算器的功能。这里的作用是将输入的十进制数转换为二进制数。
- printf “%08d\n” {}: printf命令用于格式化输出数据。%08d表示输出数字格式为8位长度的十进制数,前导位用0填充。最后的\n表示换行。
- xargs -I {}: xargs命令用于将标准输入转换为命令行参数。-I选项指定用{}表示xargs传递的参数。这里的作用是将命令行参数{}传递给printf命令。
- tee命令会将输出同时写入ttl_2.txt文件和终端屏幕。
测试过没问题后,将head改成cat,全部转换,要等一小会,可能我这thinkpad有点垃圾,最后取出八位二进制的前两位
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads/Compressed/0bf565e00b864f4ba06efc858056c7e9] |
- cat ttl_2:cat命令用于将文件的内容输出到标准输出,这里将文件ttl_2的内容输出。
- awk ‘{print substr (0,1,2)}’:awk命令用于处理和分析文本数据。在这里,通过substr函数取每一行(0)的前两个字符,然后使用print打印出来。
- tr -d “\n”:tr命令用于转换和删除字符。-d选项指定删除字符,”\n”表示删除换行符。这里的作用是删除awk命令的输出中的换行符。
- bin_ttl:>操作符用于将命令的输出重定向到文件bin_ttl中,这里将处理后的结果输出到文件中。
将文件导入cyberchef解码一下,得到一个只有部分二维码的图片
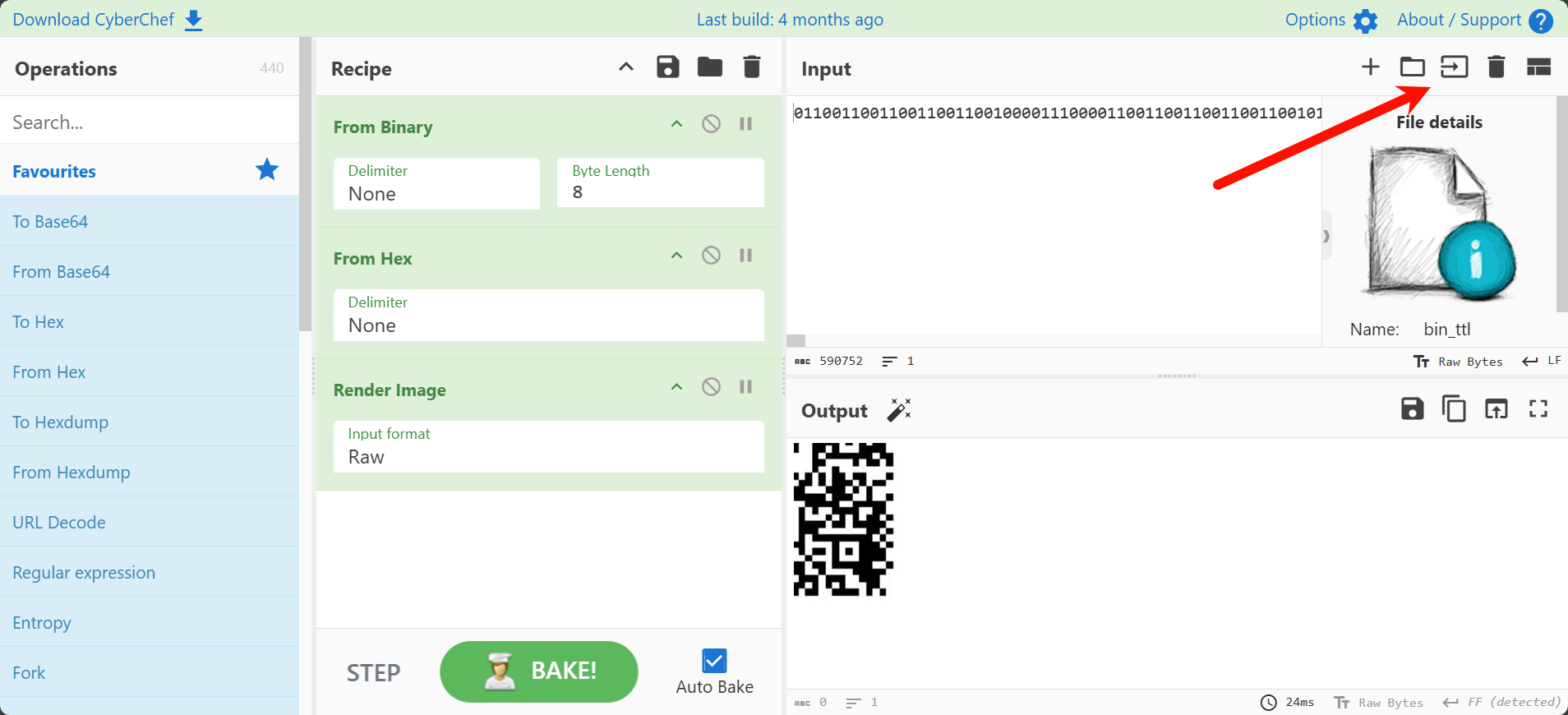
那图片大概率还是藏了东西的,保存图片,binwalk分析下
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
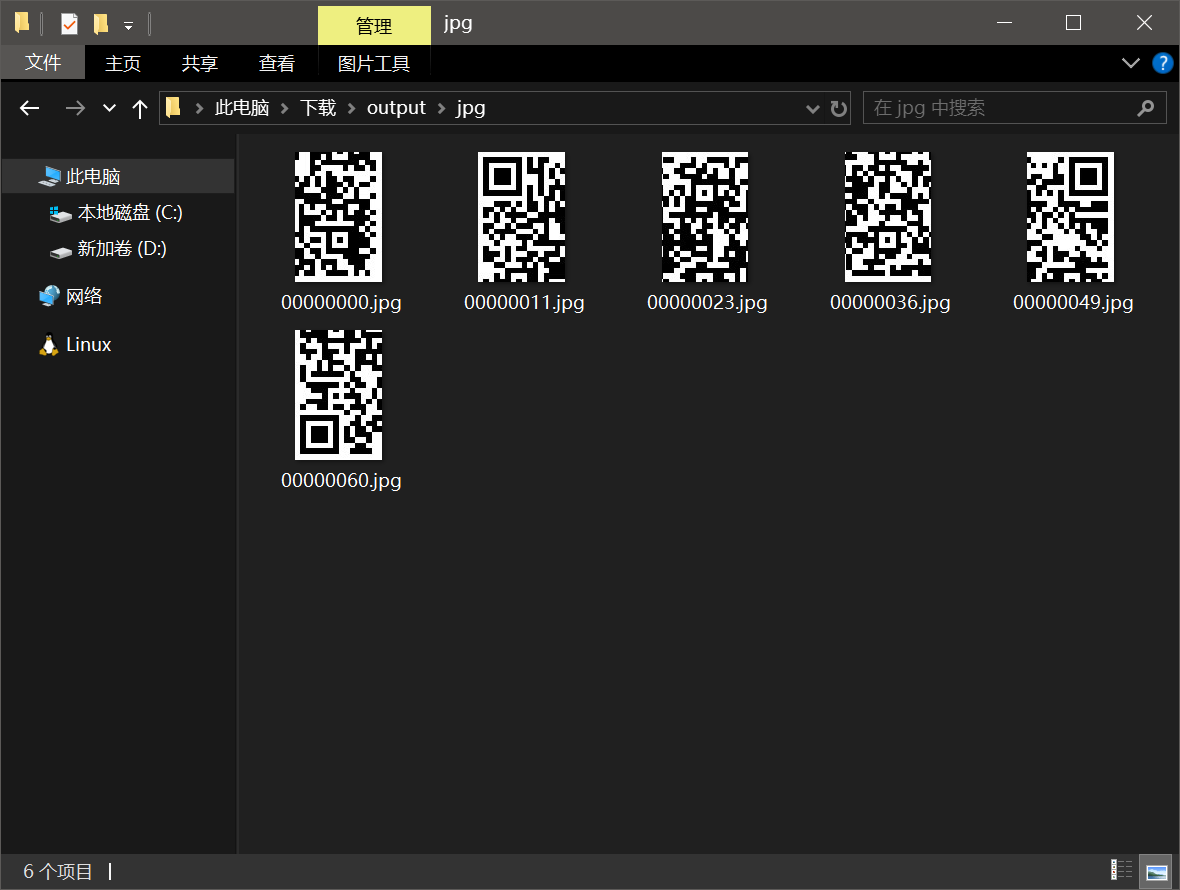
利用在线photoshop拼回去就行了
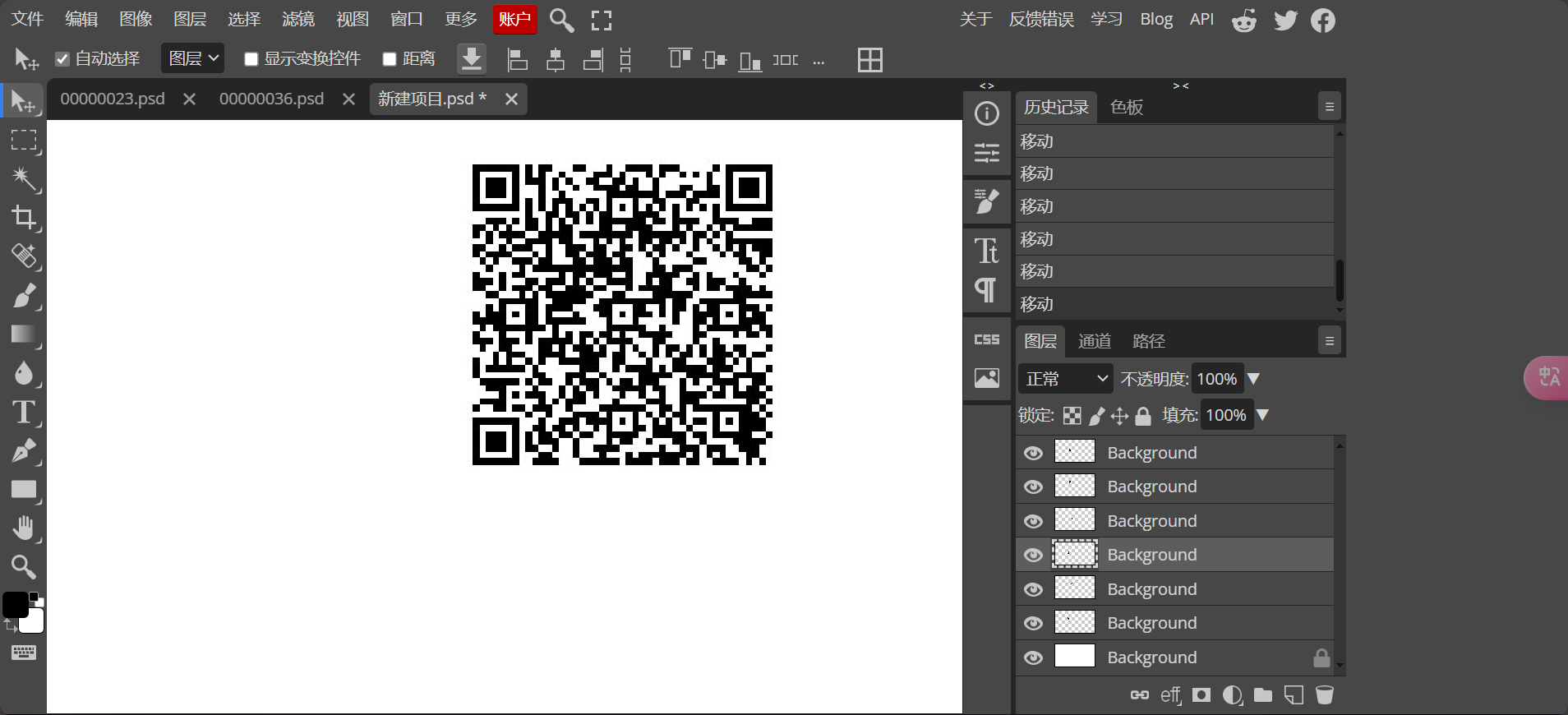
最后得到一张完整的二维码,解码后的得到key:AutomaticKey cipher:fftu{2028mb39927wn1f96o6e12z03j58002p}
通过wiki得知是自动密钥加密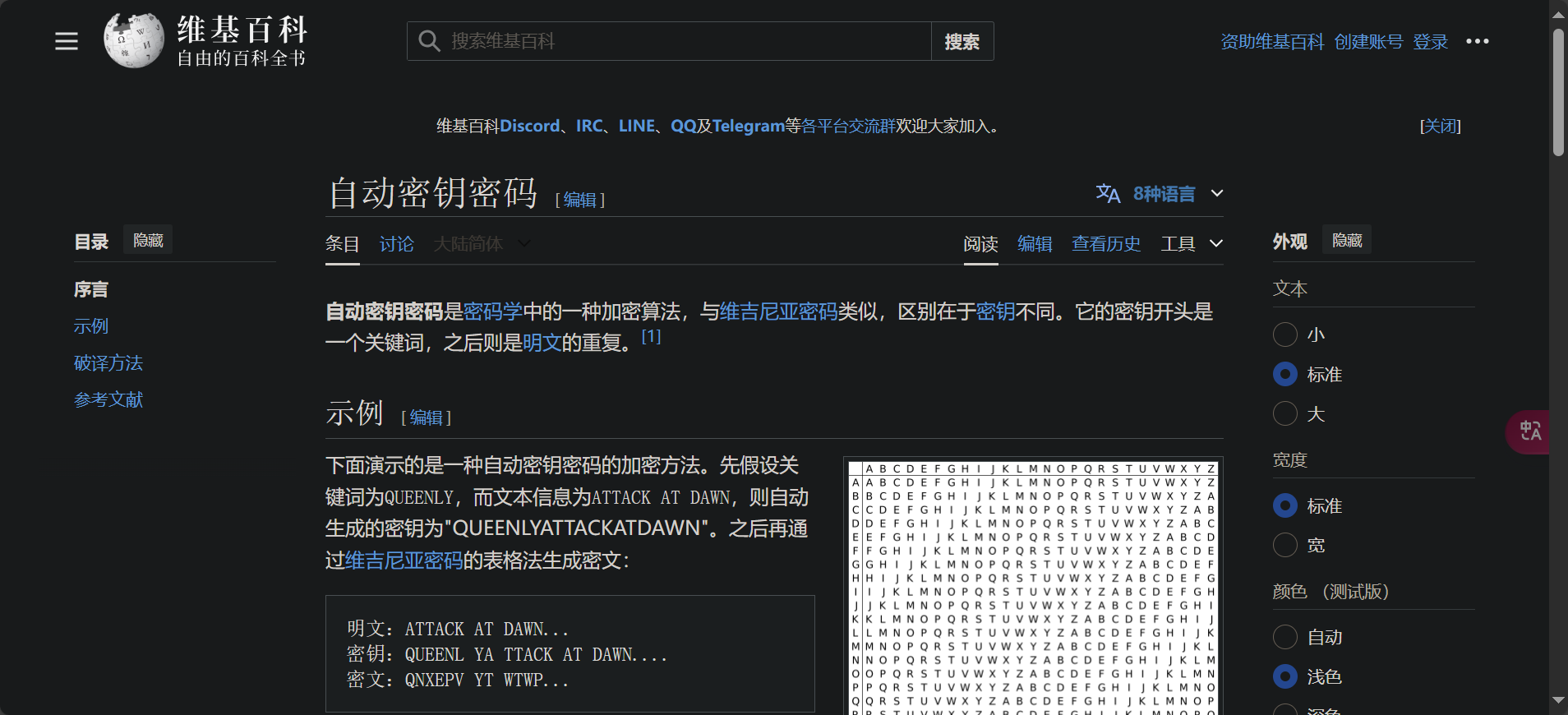
随便找个在线网站解密得到flag
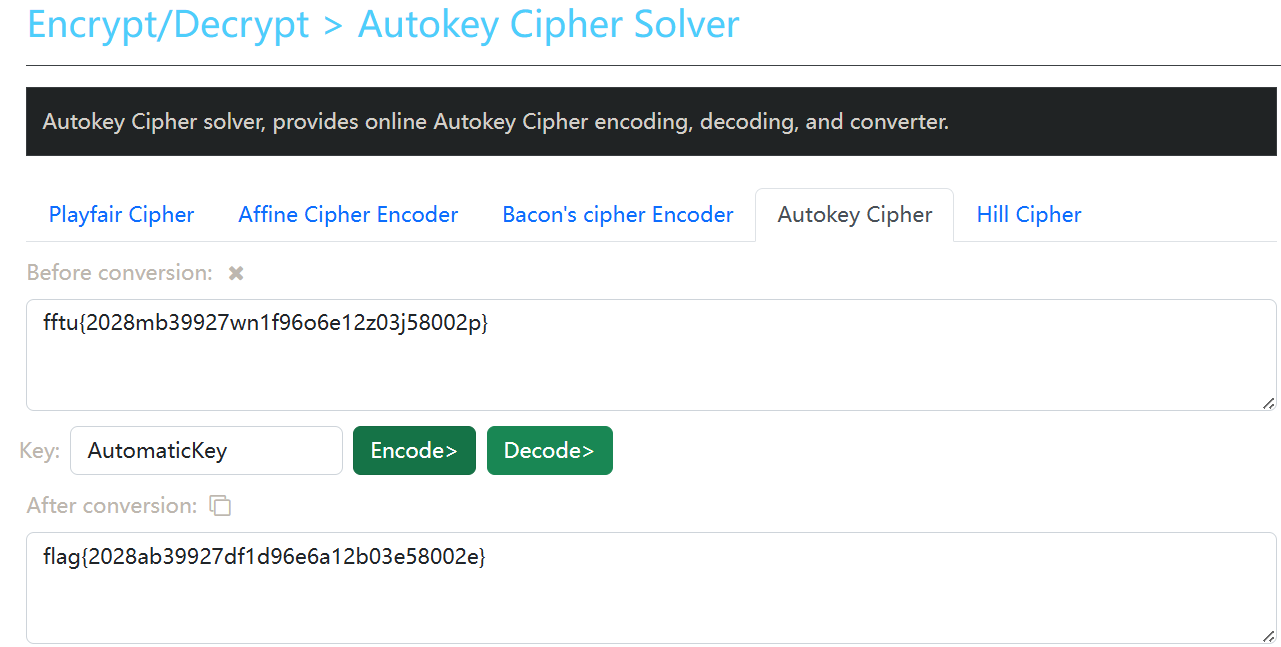
Become_a_Rockstar
文件分析
拿到是个后缀为.rock的文件,直接就搜一下rock在线打开
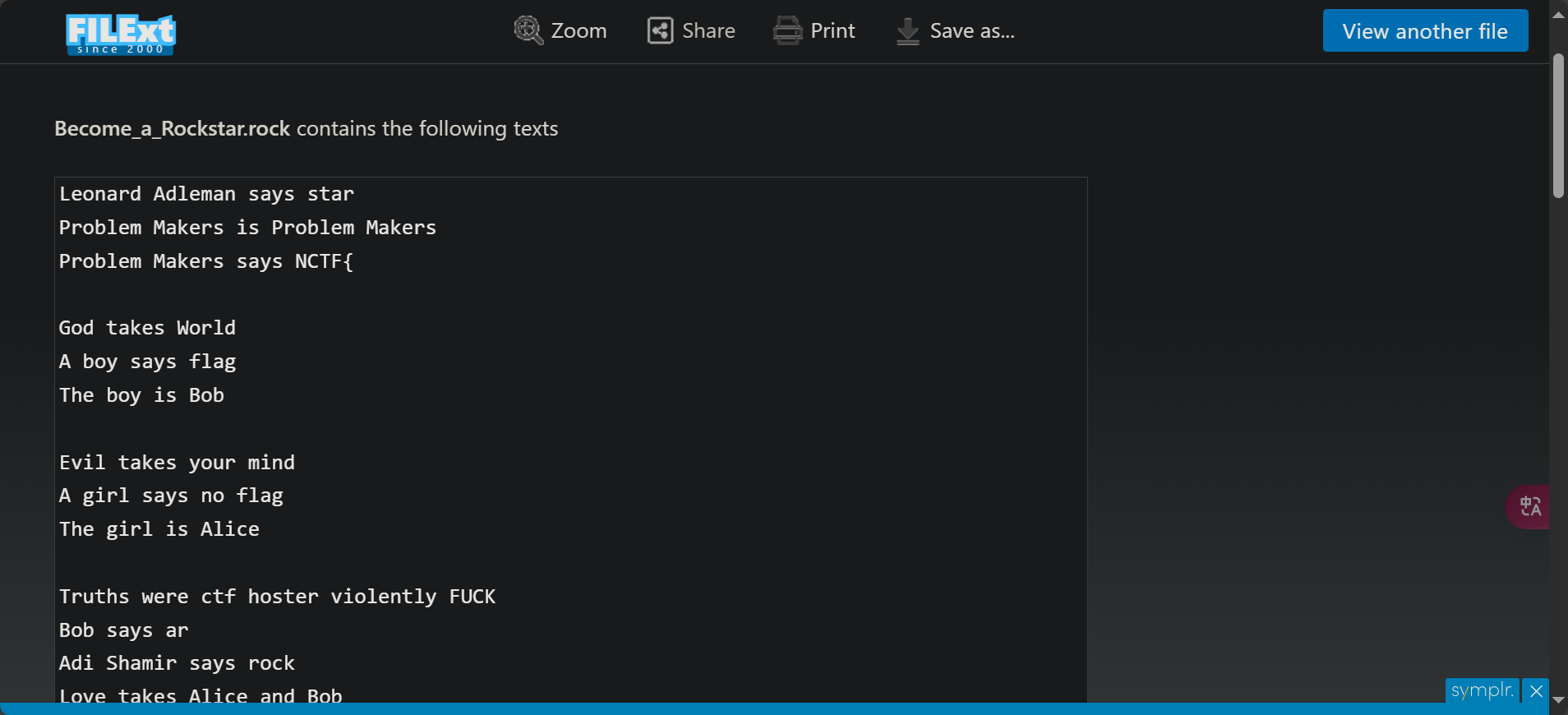
文本似乎给我们一个tips大概就是跟RSA加密有关,但实则不然,完全给你引导坑里去了
翻译了下,我看了半天的小作文,实在没搞懂
后面问了下GPT,显然rock也是一个编程语言
“rock”也可能指代以下内容:
- Rock文件格式:某些特定应用程序、游戏或设备可能会使用“.rock”作为文件扩展名来识别和打开特定类型的文件。例如,Rockbox音乐播放器软件使用“.rock”文件扩展名来存储其插件文件。
- 艺人姓名:Rock也可能是一些艺人或乐队的艺名,代表着他们的音乐风格和风格。
- 编程语言:Rock也是一种计算机编程语言和开发工具,用于开发软件和应用程序。
- 其他应用场景:除此之外,“rock”还可以用作动词,表示来回摆动或晃动,也可以代表坚固和稳固的含义。在不同的上下文中,“rock”可能有不同的含义和用法。
github上找到rock转python的脚本,直接用就行了
yyyyyyyan/rockstar-py: Python transpiler for the esoteric language Rockstar
然后python运行下就出结果了
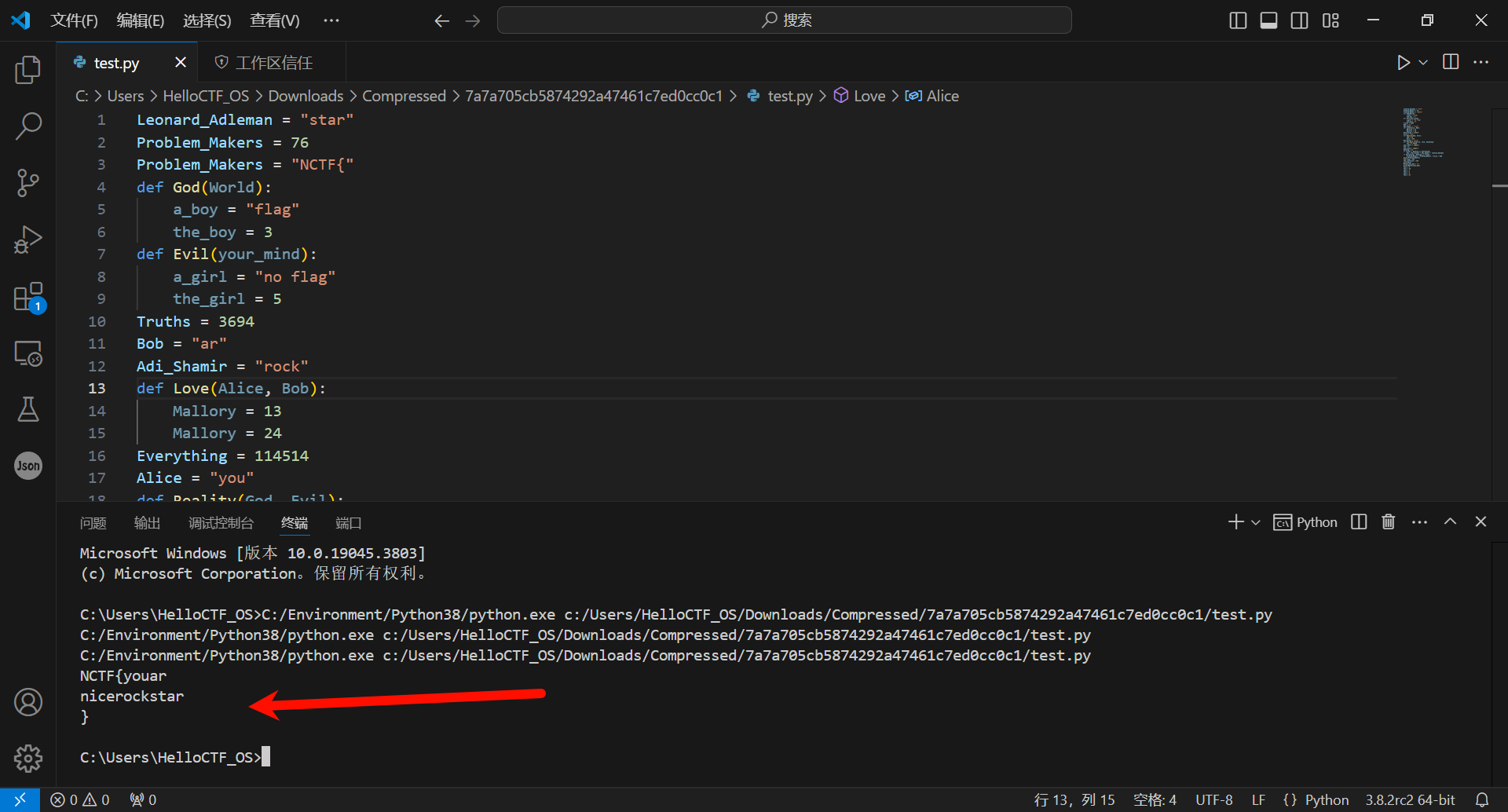
最终的flag去掉空格就行了
A-Weird-C-Program
空白字符隐写
下载下来是个C++的源文件,我尝试利用gcc进行编译运行,显然报错了
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
提示没有codeme.h这个文件,那方向就不是这里了,当我尝试在VsCode中全选文本时,可以发现
代码间充满了空格和制表符,然后还很有规律的每一行后面都有个Table制表符,大概率是分离每行的信息

尝试使用sed 将不是空格和制表符的全部删除
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
- ‘s’是sed中的替换命令,用于查找和替换文本。
- ‘{^ \t}’是一个正则表达式,用于匹配不是空格或制表符的任何字符。##这里的花括号代指中括号,注意\t前面有个空格
- ‘//‘是用于分隔要匹配的模式和要替换的文本的定界符。
- 最后的’g’代表全局,意味着它会在每一行上替换模式的所有出现
验证一下有没有替换成功
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
再次使用sed将空格替换成0,制表符替换成1
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
可以看到已经差不多了,但是还不够,一般二进制转成ASCII都是八位八位转换的,所以每一行只取后八位,还是利用sed
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
还有个问题,每一行后的换行符下紧跟的1如何将他变为空格呢?
sed只逐行
1 | ┌──(ctf㉿Hello-CTF)-[/mnt/c/Users/HelloCTF_OS/Downloads] |
‘:a’:这是一个标签(label),使用冒号开头。标签的作用是在sed脚本中定义一个位置,用于跳转或引用。
‘N’:这个命令表示将当前行与下一行一起添加到模式空间中,形成一个多行文本。
′$!ba’:这是一个条件语句。”$”‘ 表示最后一行,’!’ 表示“非”。因此’$!ba’表示如果不是最后一行,则跳转到标签’a’,实现循环处理多行文本的效果。
在 sed 命令中,
!表示逻辑非,它用于条件控制语句。在!ba中,b是 sed 中的分支(branch)命令,用于无条件转移到指定标签位置,a则是一个标签名称。因此,!ba的意思是如果不是最后一行,则分支(branch)到标签a的位置,即执行无条件跳转到标签a的操作。这样可以实现多行文本的处理和循环处理操作。‘s/\n1//g’:这是sed的替换命令。它会查找换行符(\n)后面紧跟的字符”1”,并将其替换为空(删除)。斜杠(/)用作分隔符,g代表全局替换,即每行中的所有匹配项都会被替换。
最后利用Cyberchef将二进制转为ASCII
我们生活在南京-2
音频隐写题
在交流过程中发声音被干扰,于是使用了更加稳定的方法(CW)(字母全小写,请在合适的位置添加大括号)
音频文件拿到手听了一下,没有什么显著特征,不是SSTV听起来也不是morse code ,全是杂音
看了下描述采用了CW方法,好在我还了解一点无线电CQCQ是结束通联,CW等幅电报通信(Continuous Wave)是利用morse code进行通联,那放进audacity分析下
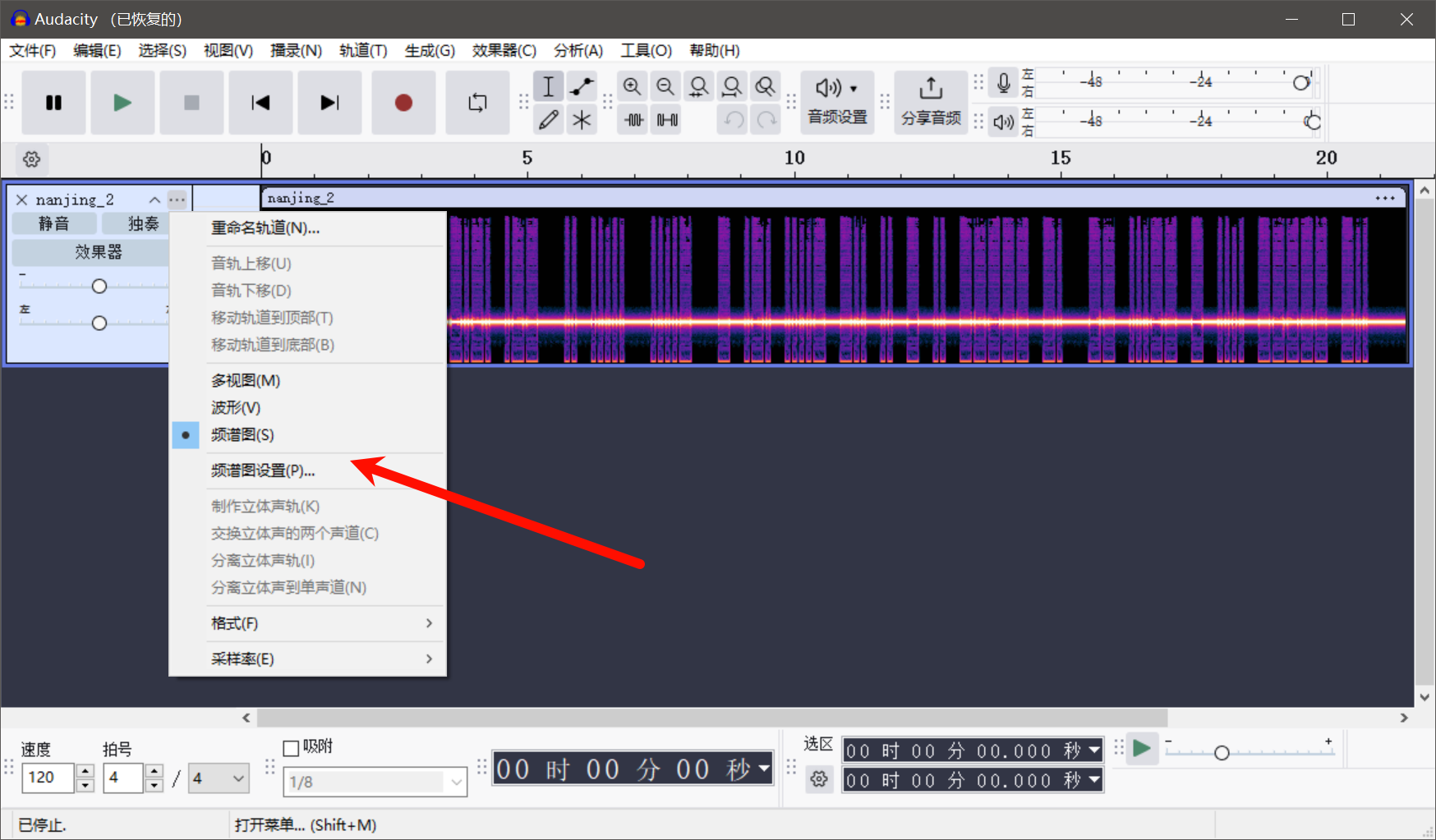
切换到频谱图,发现关键信息,短竖线为.,宽竖线为-,通过cyberche即可解的flag,再全转为小写就行了