
有些题目没法赛后复现,只能借鉴其他师傅的WP了
签到
网安知识大挑战
这题我们队是在最后做出来的,比较菜,刚开局没做我没做这题,反倒最先做出来是Misc01
打开网址是以vue为框架的页面,只有全部题目做对才给flag
在网页的js源文件中Ctrl+F搜索DASCTF关键字可以搜到关键信息,随便翻翻可以找到题目对应的答案


最后提交就给出flag了
其实还有另一种更快的方式,你仔细观察发现flag数据就在源码中,只不过进行了AES加密了
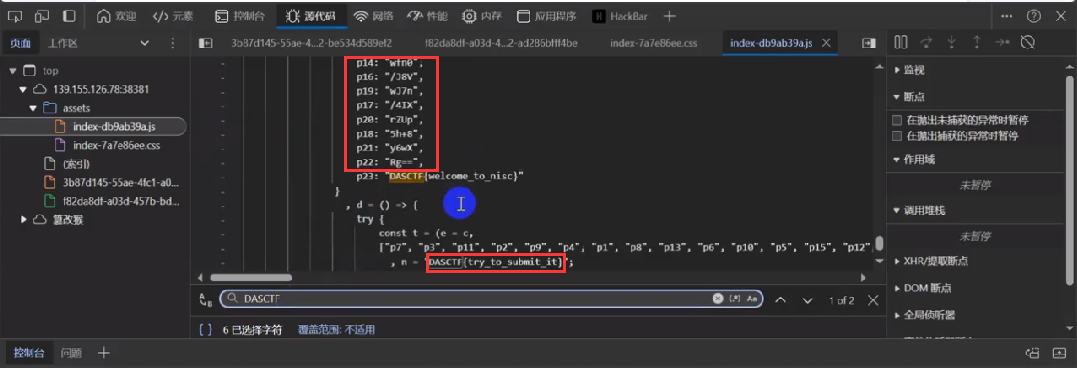
这里引用其他师傅更加清晰的图片,从p7到p22文本进行处理一下,最后再进行AES解密即可,key则为图中n的变量


签到题
欢迎来到2024年浙江省大学生网安竞赛,下面是一个签到题,解码即可获取flag,flag格式为 DASCTF{xxx},提交flag时只需要提交括号内的内容。
6L<Ak3,@VM*>7U&FZFNWc,Ib=t,X!+,BnSDfoaNhdiO][5F];eV^]Lm&?$’<oeGH&6tqcgK_JDp-3;8wh?Si,G$BarTFjE?b$eR/,Igij<({u90M$5If589[<4+jp%3_%R(526#1J|m5p&H+%.#d0<DmLK*#-\8w:xD2Y[3jO{l8[)<(F[=Bcixb>Jp^%L2XvVTzW@9OTko/P74d1sFscEbMO7Vhp&HM;+ww/v[KM1%2M*7O}rEZM.LM0’\iwK:])pg-nJef\Rt4
这签到题我硬生生没做出来,难受了,还是题目做的太少了,典型的套娃题,这里被CyberChef误导了好久,这个编码工具有个功能就是自动识别编码类型,点击魔法棒即可自动帮你完成解密,这里提示是HTML Entity加密,比赛结束看WP才知道
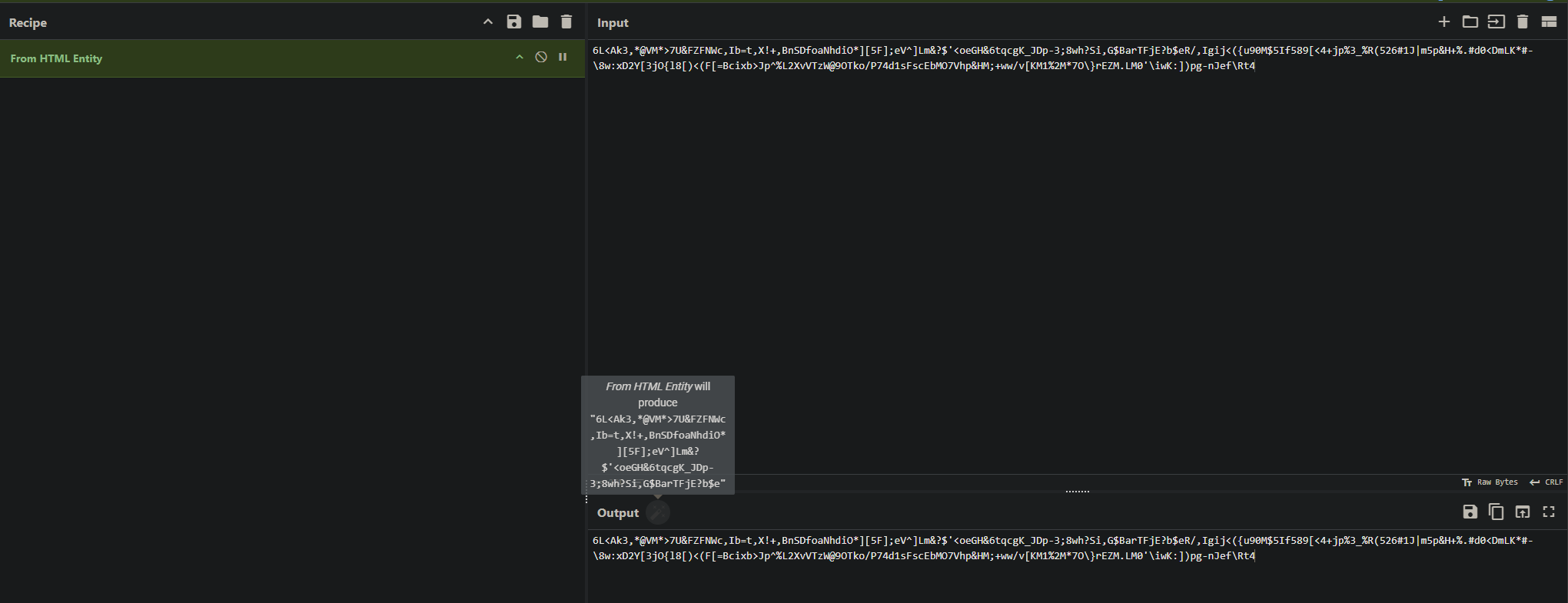
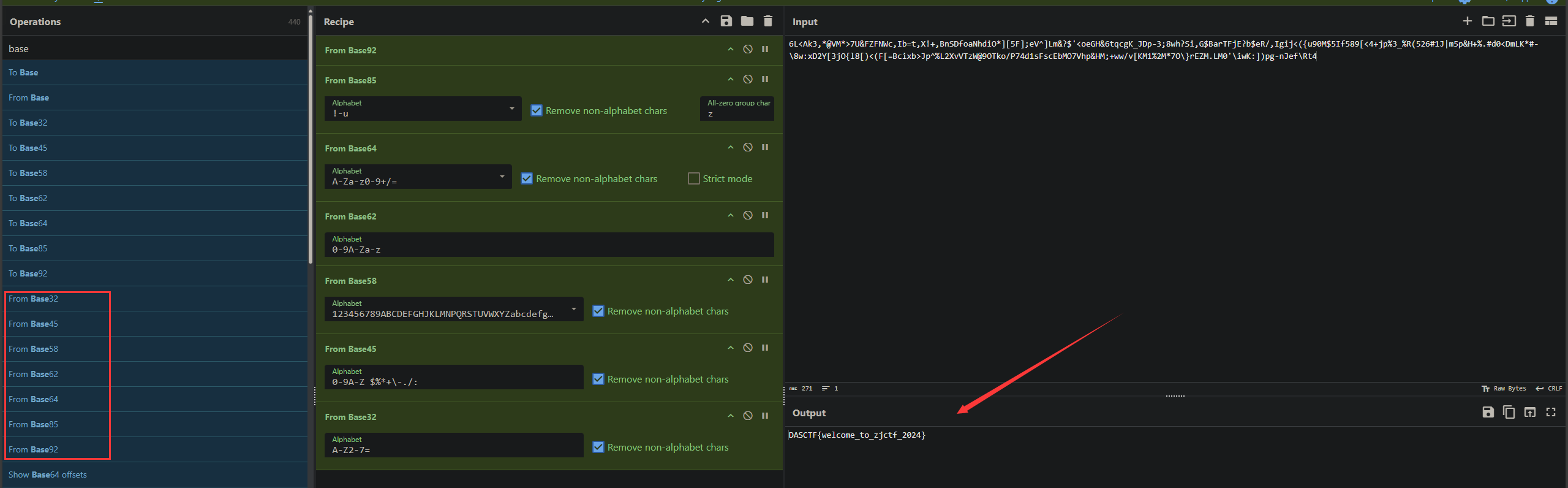
其实直接CyberChef将BASE家族的编码全部点一遍即可
Web
easyjs
这题没法赛后复现,不过也可以了解下解题流程
题目给了附件,就是网页源代码
1 | const express = require('express'); |
- 首先,从请求的headers中获取’note-id’字段的值作为noteId变量。
- 然后,检查noteId是否存在以及对应的note是否存在。如果noteId不存在或对应的note不存在,则返回状态码403和错误消息’Authentication required’。
- 接着,检查对应的note是否有isAdmin字段,如果没有则返回状态码403和错误消息’Admin access required’。
- 然后,尝试读取文件’/flag’的内容作为flag变量,并将其去掉首尾空格后返回给客户端。
- 如果读取文件时出现错误,会返回状态码500和错误消息’Error reading flag’。
当你访问/api/notes的时候会提示Missing id因为你的请求头headers没有指定noteId所以可以新建一个笔记id随便取名字,只要isAdmin字段为True

然后再次访问/api/flag在请求头headers中设置note-id字段为你上面取的名字,即可获取flag

hack memory
由于没有附件,后续也无法复现,总结就是通过扫目录发现有个upload目录,直接上传个木马即可,方案有很多反弹Shell 冰蝎 蚁剑在根目录即可找到flag文件cat /fffffllllagggg就行了
这里推荐一个反弹Shell的网站 https://www.revshells.com/

QL_again
附件到手是个jar文件,java涉及到盲区了,尝试利用java启动一下,发现是个基于spring boot框架的,不会,遂放弃
Misc
RealSignin
这题我觉得算是最简单的了,是真签到题,比起上面的签到来说,附件到手就是一个图片
利用zsteg直接梭哈,发现除了PNG内容外有个额外数据信息,大概率就是密文了,而且发现再lsb 通道中发现加密的字母表
1 | ┌──(kali㉿kali)-[~] |
如果没装可以
sudo gem install zsteg装一下
利用CyberChef进行Base64换个表解密下就出来了
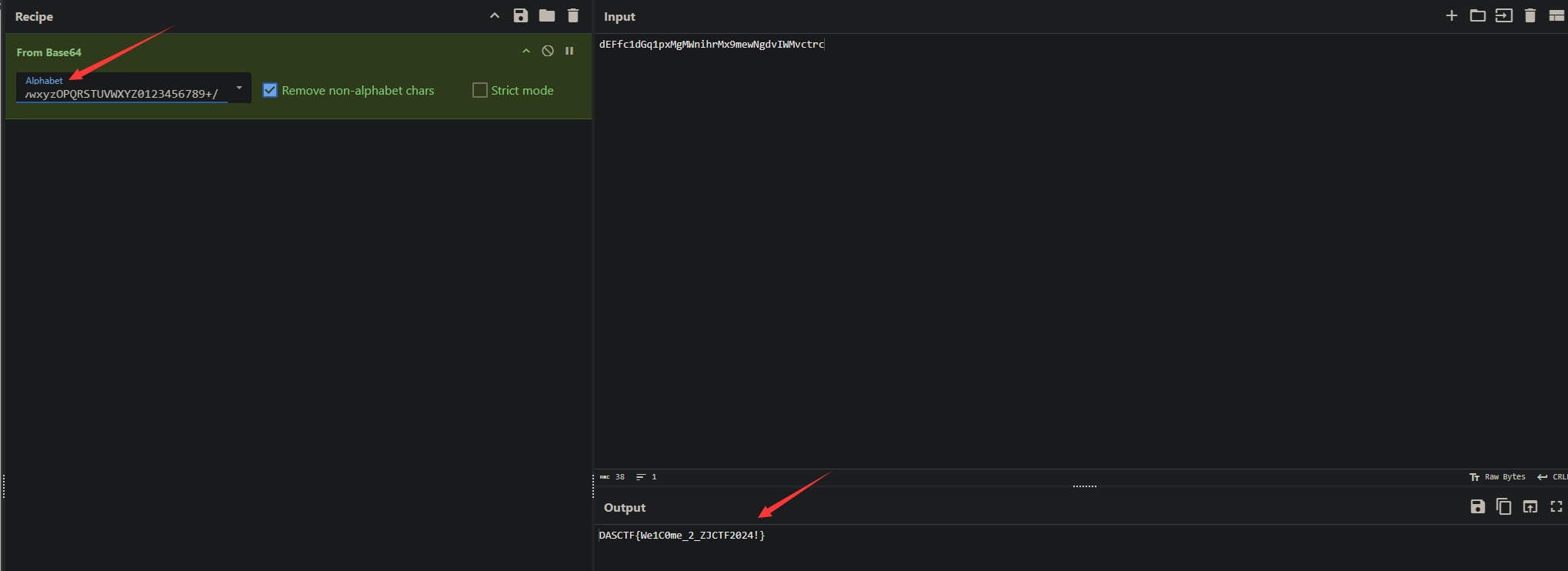
机密文档
拿到附件是个加密的压缩包发现压缩包里还有个压缩包the_secret_you_never_ever_know_hahahaha.zip,这题我头都大了,一直在John无脑爆破,当我丢进PasswareKit Forensic再尝试下发现这个可以进行zip明文攻击,不过当时没做出来
这里我们可以在Github上找到bkcrack这个zip明文攻击工具,在release中下载编译好的文件直接运行即可
但是这个竞赛又不让主动访问互联网,做个头啊,只能怪自己没有做到类似的题目,提前安装
1 | ┌──(kali㉿kali)-[~/Desktop/bkcrack-1.7.0-Linux] |
发现是个ZipCrypto加密同时又是Store未压缩的,这恰恰符合明文攻击的特征,推测the_secret_you_never_ever_know_hahahaha作为明文
明文攻击主要利用大于 12 字节的一段已知明文数据进行攻击,从而获取整个加密文档的数据。也就是说,如果我手里有一个未知密码的压缩包和压缩包内某个文件的一部分明文(不一定非要从头开始,能确定偏移就行),那么我就可以通过这种攻击来解开整个压缩包。比如压缩包里有一个常见的 license 文件,或者是某个常用的 dll 库,或者是带有固定头部的文件(比如 xml、exe、png 等容易推导出原始内容的文件),那么就可以运用这种攻击。当然,前提是压缩包要用 ZipCrypto 加密。
reference:https://www.poboke.com/crack-encrypted-zip-file-with-plaintext-attack.html
一般来说密文也就是the_secret_you_never_ever_know_hahahaha.zip的开头部分并不是明文the_secret_you_never_ever_know_hahahaha所以需要指定偏移量,偏移30字节,偏移后的明文就是zip的文件头
504b030414000000
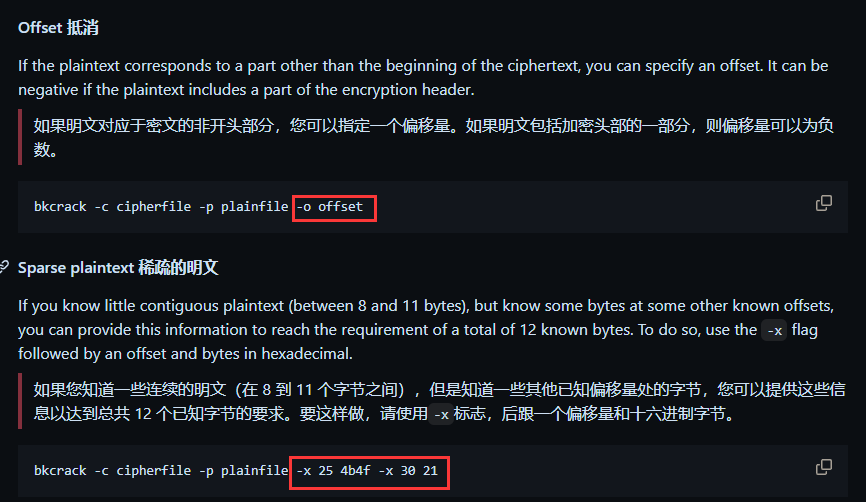
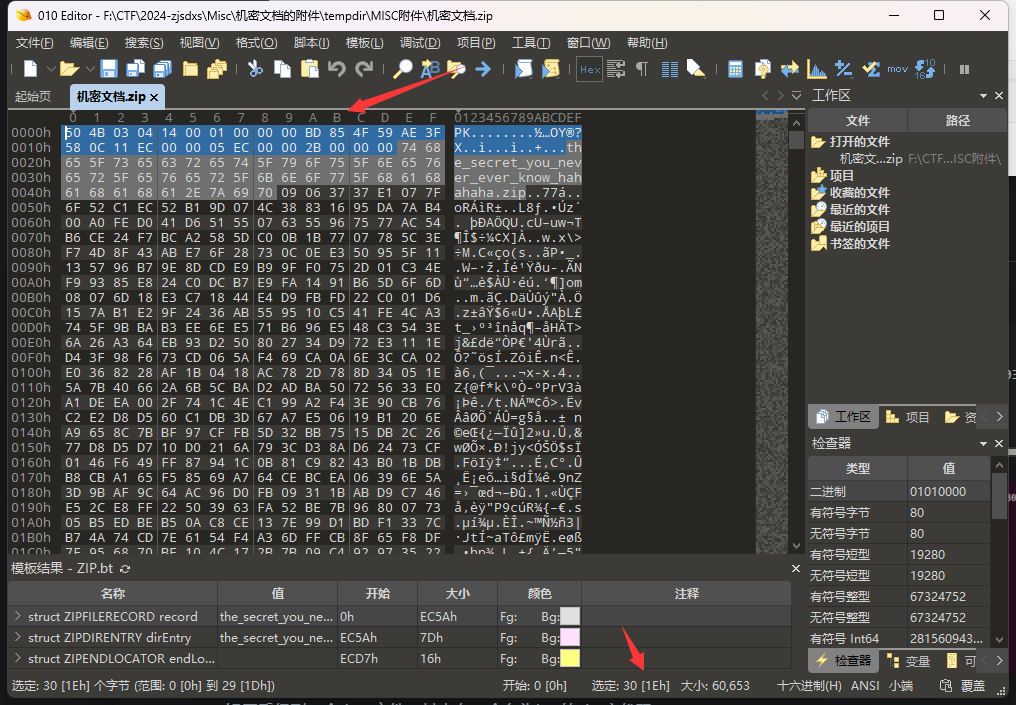
1 | ┌──(kali㉿kali)-[~/Desktop/bkcrack-1.7.0-Linux] |
- -C 加密的压缩包
- -c 存在明文的文件
- -p 存储了明文的文本
- -o 抵消指定偏移量
- -x 偏移值 十六进制字节数据
- -k 已知
key- -U 使用已知的
key将压缩包改成密码为easy并新生成一个decode.zip
1 | ┌──(kali㉿kali)-[~/Desktop/bkcrack-1.7.0-Linux] |
在Microsoft Word中尝试打开有个安全提示宏已被禁用,其中word中还有一张png图片
其实不用打开word也大概能猜到是带宏的文档,关于word这类的题目大多都是这样
我们启用宏内容,在视图-宏-查看宏可以发现名为key的宏文件,或者alt+f8也行

1 | Sub key() |
说白了就是将decValues数组中的数字和str字符串outguess进行进行异或运算,并将结果存储到xorValue中,异或运算的结果转换成字符,然后拼接到result字符串中,很简单的一段代码
利用python将答案复现,
1 | a=[26, 25, 28, 0, 16, 1, 74, 75, 45, 29, 19, 49, 61, 60, 3] |

根据关键字outguess其实就能猜出这是个图片隐写,word中的图片就是隐藏信息的图片
不要使用word中的图片另存为功能
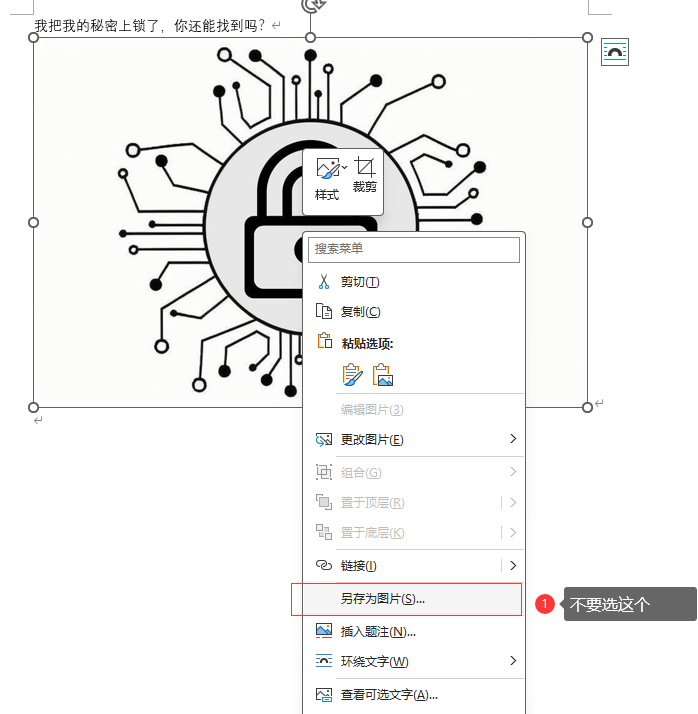
将docm后缀名改为zip解压打开,可以在the_secret_you_never_ever_know_hahahaha\word\media路径下找到源文件,相比发现源文件会比另存为多一些内容,再将image1.jpeg改为image1.jpg否则outguess不认,我也不知道为啥,可能原来的文件就是jpg只不过被word改了
1 | ┌──(kali㉿kali)-[~] |
如果没装outguess可以执行
sudo apt install outguess另外如果不想使用word查看宏也可以装个
python-oletools工具包中的olevba如果你既不想装这装那,还有个在线网站可供你提取
vbahttp://tools.bugscaner.com/office/word-parser-vba.html
执行
pipx install oletools即可使用olevbaolevba 是一个用于解析 OLE 和 OpenXML 文件(如 MS Office 文档(例如 Word,Excel)的脚本,以检测 VBA 宏,提取其源代码以明文显示,并检测安全相关模式,如自动执行宏,恶意软件使用的可疑 VBA 关键字,反沙箱和反虚拟化技术,以及潜在的 IOCs(IP 地址,URL,可执行文件名等)。它还检测和解码几种常见的混淆方法,包括十六进制编码,StrReverse,Base64,Dridex,VBA 表达式,并从解码的字符串中提取 IOCs。XLM/Excel 4 宏也受支持,可在 Excel 和 SLK 文件中使用。
EZtraffic
看到附件名字就猜到是个流量分析题了,打开wireshark看了一下,大多都是smb2的报文,使用wireshark - 文件 - 导出对象 - SMB导出smb的全部文件,发现有个压缩包打开发现添加了注释
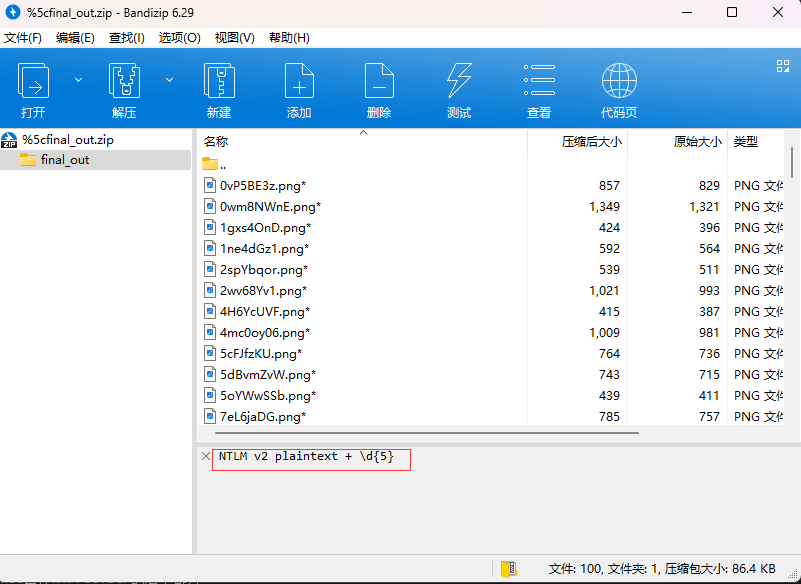
提示是NTLM V2明文+5位数字,大概率就是压缩包的密码,那我们先尝试获取NTLM V2的明文
在wireshark中找到两个主要的报文STATUS_MORE_PROCESSING_REQUIRED (0xc0000016)和NTLMSSP_AUTH,User:MicrosoftAccount\rockyou图中就简称srecv和csend
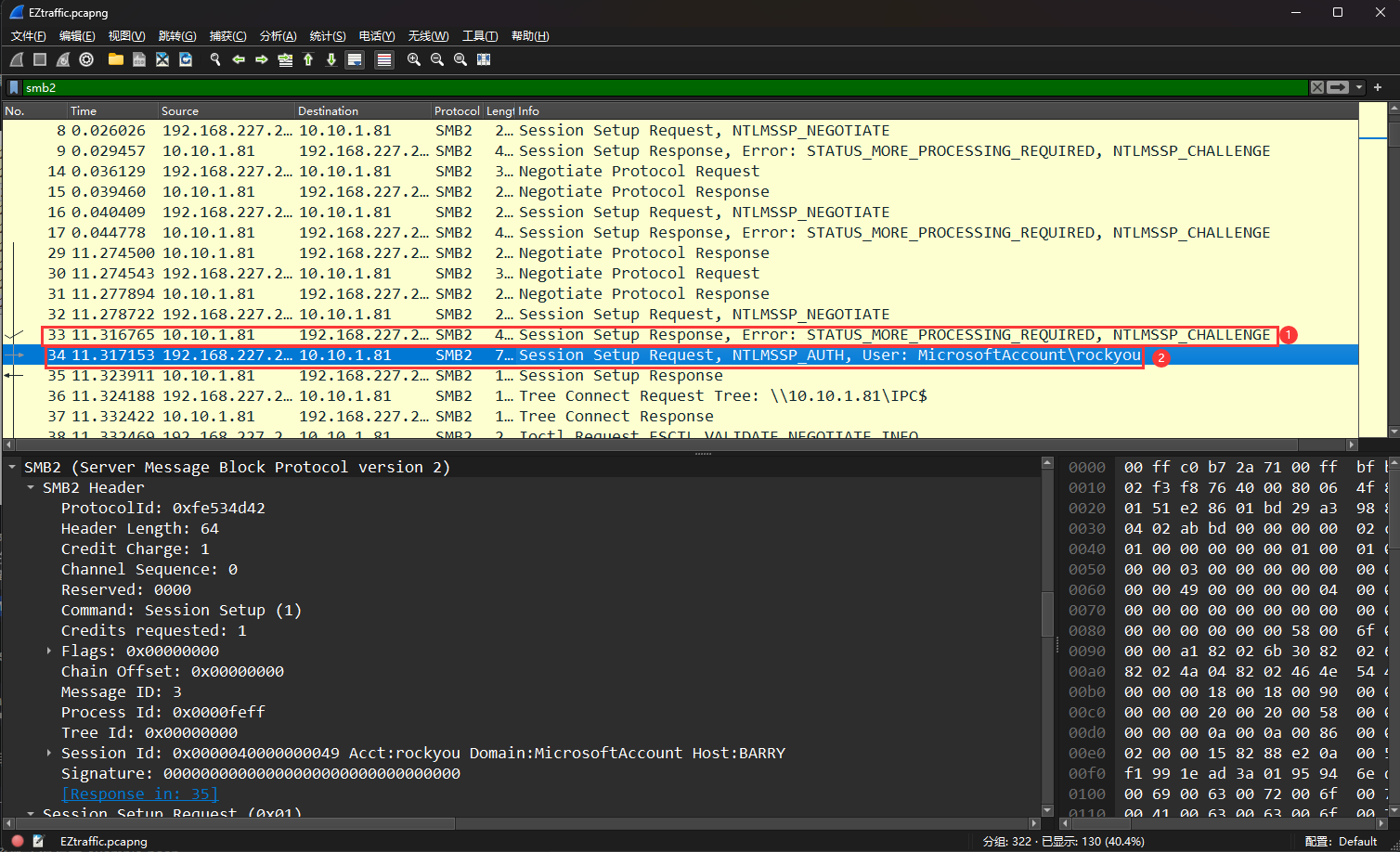
NTLMv2的格式为:
1 | username::domain:challenge:HMAC-MD5:blob |
其中的challenge可以在srecv中找到,其他的均可以在csend中找到
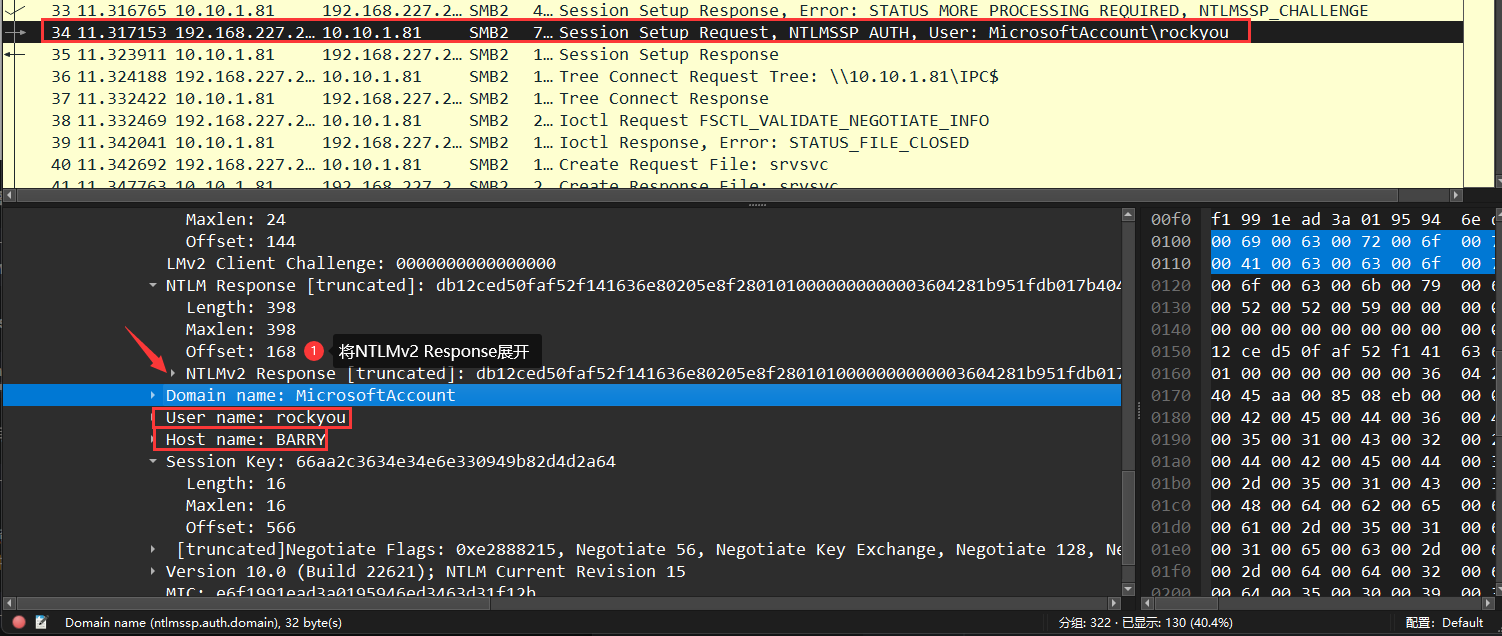
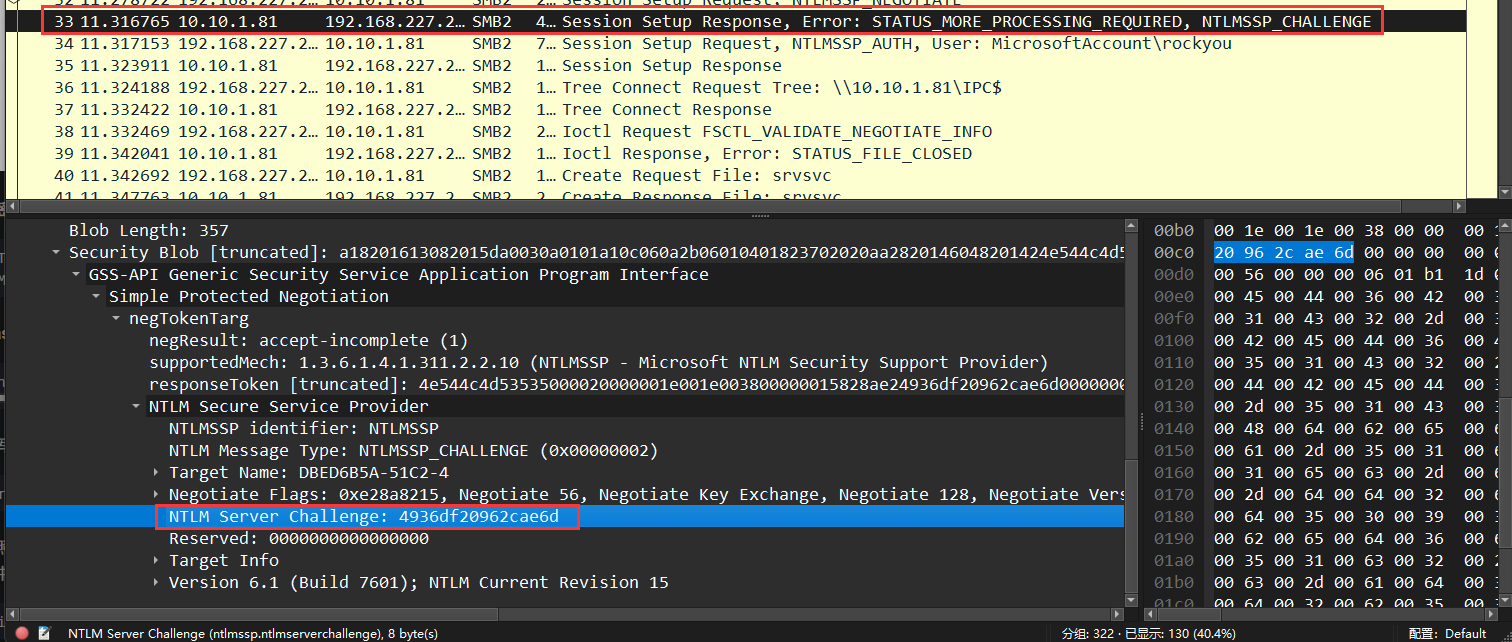
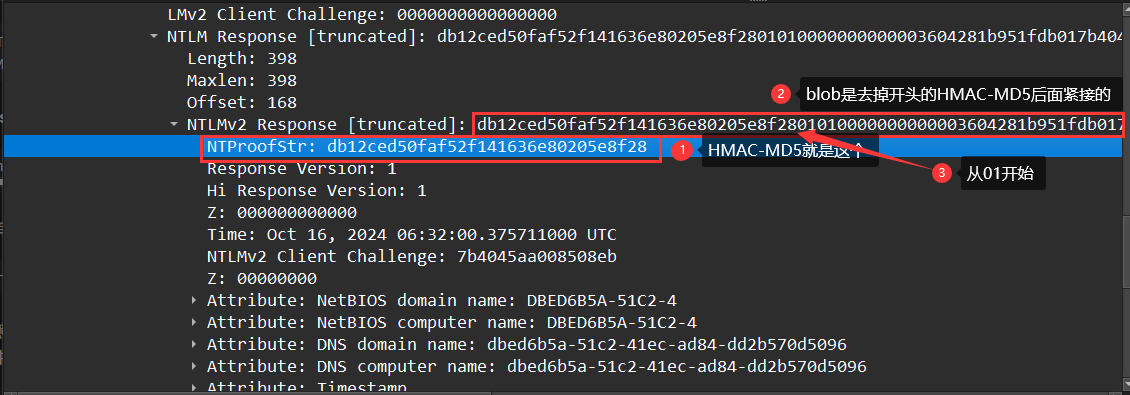
拼接后得到完整的NTLM V2
1 | rockyou::MicrosoftAccount:4936df20962cae6d:db12ced50faf52f141636e80205e8f28:01010000000000003604281b951fdb017b4045aa008508eb0000000002001e00440042004500440036004200350041002d0035003100430032002d00340001001e00440042004500440036004200350041002d0035003100430032002d00340004004800640062006500640036006200350061002d0035003100630032002d0034003100650063002d0061006400380034002d0064006400320062003500370030006400350030003900360003004800640062006500640036006200350061002d0035003100630032002d0034003100650063002d0061006400380034002d00640064003200620035003700300064003500300039003600070008003604281b951fdb01060004000200000008003000300000000000000001000000002000008029a5d8256e5c2762f439df5c06f3bc411fb0faeb3a6fa52d9273c57b09f2d10a0010000000000000000000000000000000000009001e0063006900660073002f00310030002e00310030002e0031002e00380031000000000000000000 |
通常是指网络环境下NTLM认证中的hash
NTLM认证采用质询/应答(Challenge/Response)的消息交换模式,流程如下:
- 客户端向服务器发送一个请求,请求中包含明文的登录用户名。服务器会提前存储登录用户名和对应的密码hash
- 服务器接收到请求后,生成一个16位的随机数(这个随机数被称为Challenge),明文发送回客户端。使用存储的登录用户密码hash加密Challenge,获得Challenge1
- 客户端接收到Challenge后,使用登录用户的密码hash对Challenge加密,获得Challenge2(这个结果被称为response),将response发送给服务器
- 服务器接收客户端加密后的response,比较Challenge1和response,如果相同,验证成功
尝试利用hashcat进行NTLM V2爆破,我用cpu硬解也很快
1 | ┌──(kali㉿kali)-[~] |
[!TIP]
reference:https://daiker.gitbook.io/windows-protocol/ntlm-pian/4
https://blog.csdn.net/weixin_43178927/article/details/108184017
得到密码后再根据上文提到的提示掩码爆破,再次上hashcat,先通过zip2john将压缩包的hash导出来再查询hashcat wiki得知以$zip2$*0*3*0*开头的hash为WinZip或者查看hashcat的help
1 | ┌──(kali㉿kali)-[~/zjdxs] |
得到压缩包密码为haticehatice12580
其实上面这一连串丝滑连招,可以用
ARCHPR软件直接爆破,由于我没装又懒的下所以就用hashcat了

解压打开发现疑似flag图片拆散成100张,通过StegSolve随意打开一张图片发现在LSB Red 0通道中藏有二维码,扫码后得到数字,大概率是图片的拼图顺序
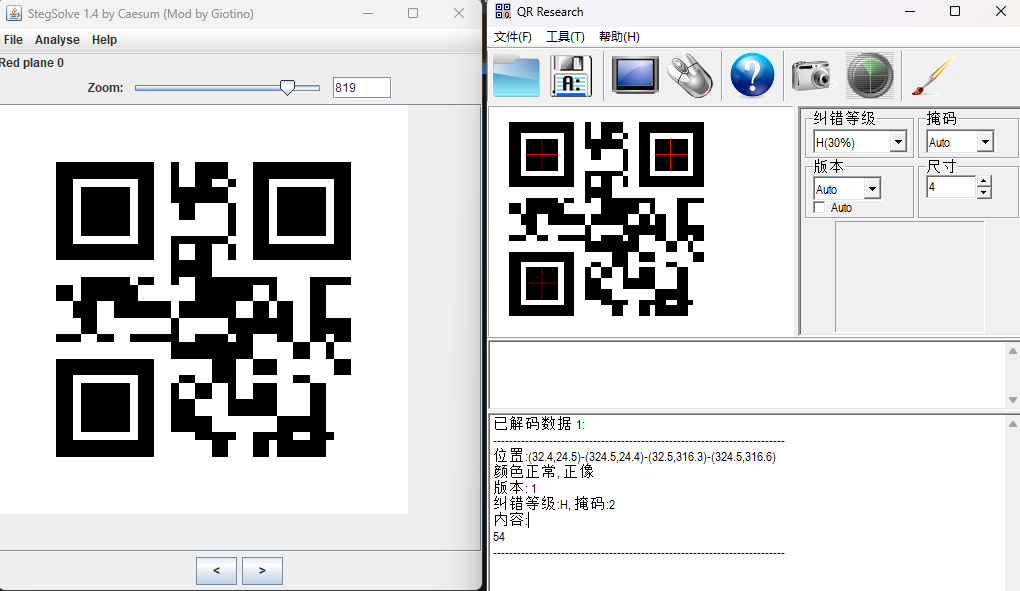
下面贴两个其他师傅写的脚本
1 | from PIL import image as Image #用于图片文件读取 |
1 | from PIL import Image |
这里我反倒觉得第二个代码更好,不过你需要新建out文件夹,他会将所有在LSB Red 0通道的二维码图片导出到out文件夹中

Crypto
Reverse
ezRe
附件到手使用file检查一下,是个python编译后的文件
1 | ❯ file ezRe |
尝试通过pycdas进行反编译
pycdas是 Decompyle++ 项目中的一个工具,它与pycdc一起工作,专门设计用来解码那些难以捉摸的 Python 3.9 至 3.12 版本的编译代码文件 。pycdas的作用是提供深度的反编译过程分析,帮助用户理解反编译的每一个细节 。它可以单独使用来打印出.pyc文件的字节码反汇编输出,这对于理解 Python 代码编译后的字节码结构非常有用,尤其是在进行代码审计或者逆向工程时 。pycdas通过提供额外的反编译信息,提升问题诊断效率 。简而言之,pycdas是一个辅助工具,用于辅助pycdc更好地进行 Python 字节码的反编译工作,尤其在面对复杂或难以反编译的代码时,pycdas能够提供更多的信息和细节 。- 我理解的是这个就类似于
IDA Pro那种反汇编的工具就可以了pycdas默认是未编译的,需要编译成exe后可以使用- 编译前需要安装
Visual Studio这个IDE见下文引用链接
得到混淆前的代码
1 | ezRe (Python 3.9) |
直接全部丢个AI让他分析下
- 导入模块:代码中导入了
base64模块,用于处理Base64编码和解码。- 输入处理:代码从用户那里接收输入,并将输入存储在变量
text中,提示信息为'Flag: '。- 密钥处理:代码中有一个固定的密钥
'7e021a7dd49e4bd0837e22129682551b',它被用于后续的加密逻辑。- RC4算法实现:代码中实现了一个简化版的RC4算法。RC4算法是一种流密码算法,它通过生成一个伪随机的密钥流来加密数据。在这段代码中,算法的核心逻辑是通过一个循环来更新一个256长度的数组
s,然后使用这个数组来生成密钥流。- 数据加密:代码中有一个列表推导式,它创建了一个列表,其中的每个元素都是通过对密钥字符的ASCII值进行XOR操作得到的。
- 验证逻辑:代码中有一个验证逻辑,它将用户输入的
text与通过RC4算法加密后的数据进行XOR操作,然后将结果进行Base64编码和解码,最后与一个固定的Base64字符串进行比较。如果比较结果相同,则输出'yes!',表示验证成功;否则输出'try again...'。- 结束:代码最后返回
None,表示程序执行结束。
直接改个RC4加密代码,把密文和密钥放进去
1 | class rc4(): |
参考:zrax/pycdc: C++ python bytecode disassembler and decompiler
Windows 如何仅安装 MSVC 而不安装 Visual Studio_msvc v143-CSDN博客
Pycdc install | Pycdas install | Pycdc And Pycdas install video | python Decompile #decompile
PWN
shellcode
数据安全
ds-enen
附件给到是个vhd文件,在diskgenius中挂载查看发现啥都木有,原来在磁盘文件中藏了点东西,用foremost分离可以得到压缩包,需要密码,没有任何提示哇,只能尝试john硬爆破了,大概率是纯数字,如果+字母和特殊符号的话时间太久了,至于为啥不用hashcat,因为hash值太长了,hashcat识别不到hash,后面还是看的wp得知是8位密码,用crunch生成8位纯数字字典,也不大800多兆吧
1 | ┌──(kali㉿kali)-[~/zjdxs/output/zip] |
使用密码60111106解压后发现是个data.csv使用Microsoft Excel打开全是乱码
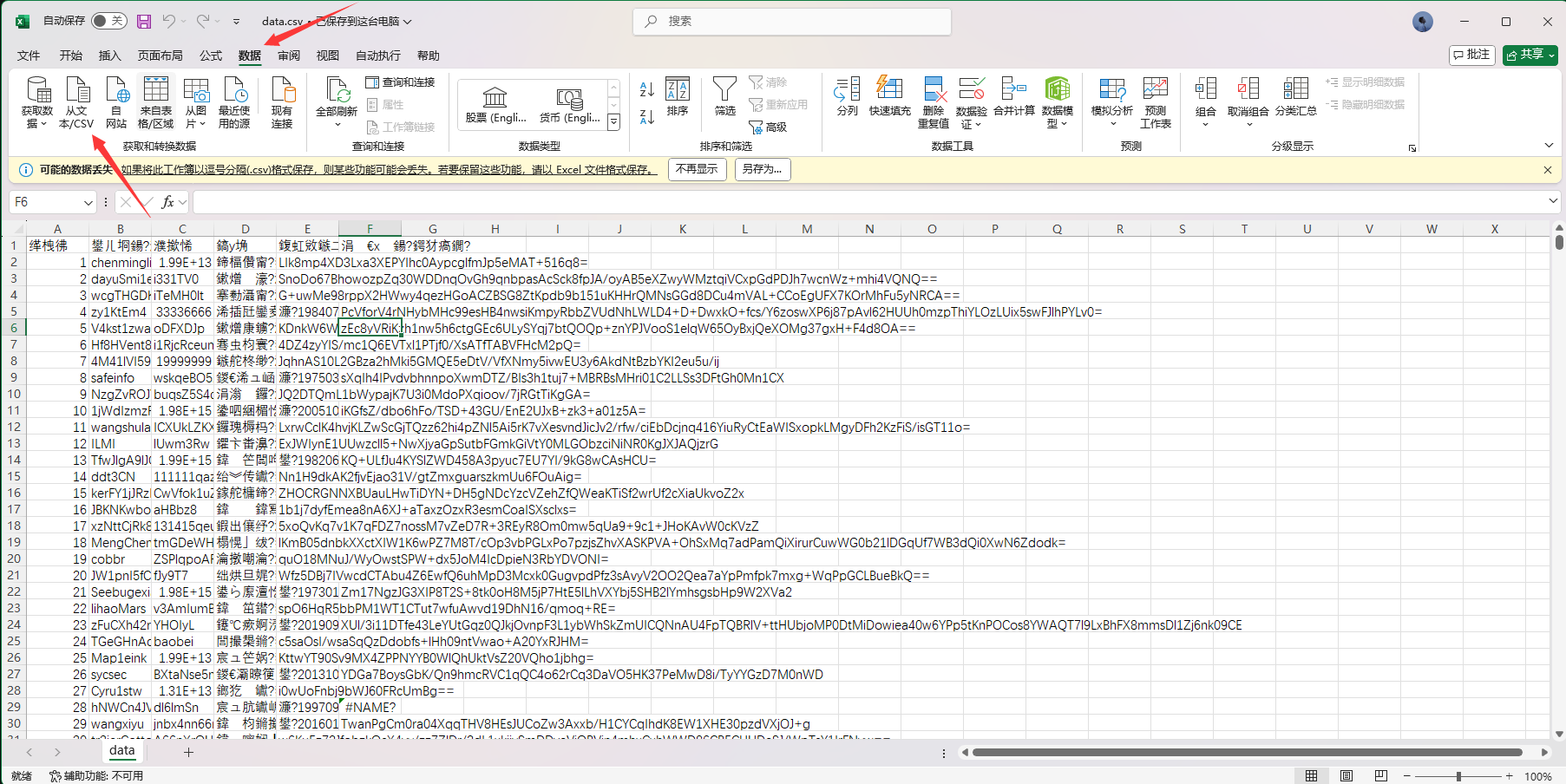
查询得知使用数据-从文本/CSV导入编码改成UTF-8即可正常显示
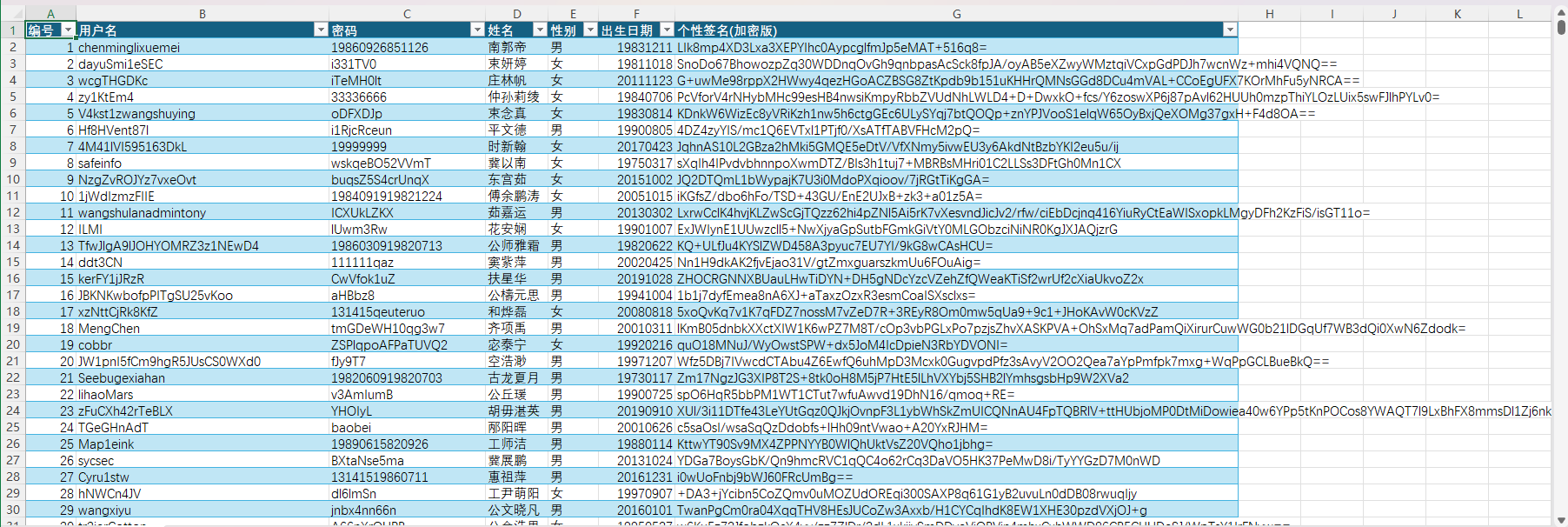
有个密码和个性签名(加密版)疑似是AES加密尝试解密下,密码为key,长度不够16位所以填充空字节位,由于是AES MODE为ECB(NoPadding)无填充所以无需填写IV
0x00(空字节)和空格是两个不同的概念。
- 0x00:0x00是一个16进制数,对应的十进制数是0。在计算机中,0x00被称为空字节(null byte),它是一个8位二进制数,所有位都为0。空字节在字符串处理中常用于表示字符串的结束或者作为字符串中的间隔符。空字节通常不显示在文本编辑器或终端中,但在内存中是存在的。
- 空格:空格是一个可见字符,在ASCII编码中对应的字符是空格符。空格用于文本中表示空白或分隔不同的单词或数字。空格在文本处理中经常被用来增加内容的可读性。在文本编辑器或终端中,空格通常可以看到并占据一定的显示空间。
这里贴一下其他师傅的脚本,使用python批量对CSV进行AES ECB解密,这两个脚本都比较类似任选其一即可
1 | from Crypto.Cipher import AES |
1 | import csv |
在Python中,
b'\0'表示一个字节序列,其中\0表示一个空字节(null byte)。这是因为Python中的字节字面值通过前缀b来表示。空字节通常用来表示字符串的结尾或作为字符串中的间隔符。在Python中,
\0对应的是空字节的ASCII字符,即NUL(NULL)字符。空字节可以在字符串处理中发挥作用,如在字符串处理和二进制数据处理时,用来表示特殊意义。需要注意的是,Python中使用\0来表示空字节,并不是所有编程语言都支持这种方式。
我将每次解密的文本都打印出来可以更加直观的看到解密的后的信息是一段话,flag就藏在其中,只要上面添加if语句即可,判断DASCTF是否在其中,就能找到flag了
1 | ┌──(kali㉿kali)-[~/zjdxs/output/zip] |
ds-encode
附件中有两个文件,PDF和ZIP压缩包,解压后得到Mysql的数据文件,由于我电脑上没装类似SQLyol、Navicat的数据库管理软件,正巧我电脑有PHPStudy以前用来玩本地Web靶场的,直接将数据库文件拷贝到PHPStudy的Mysql文件夹中

启动了Mysql和Nginx打开phpMyAdmin网页,用户名和密码都是root
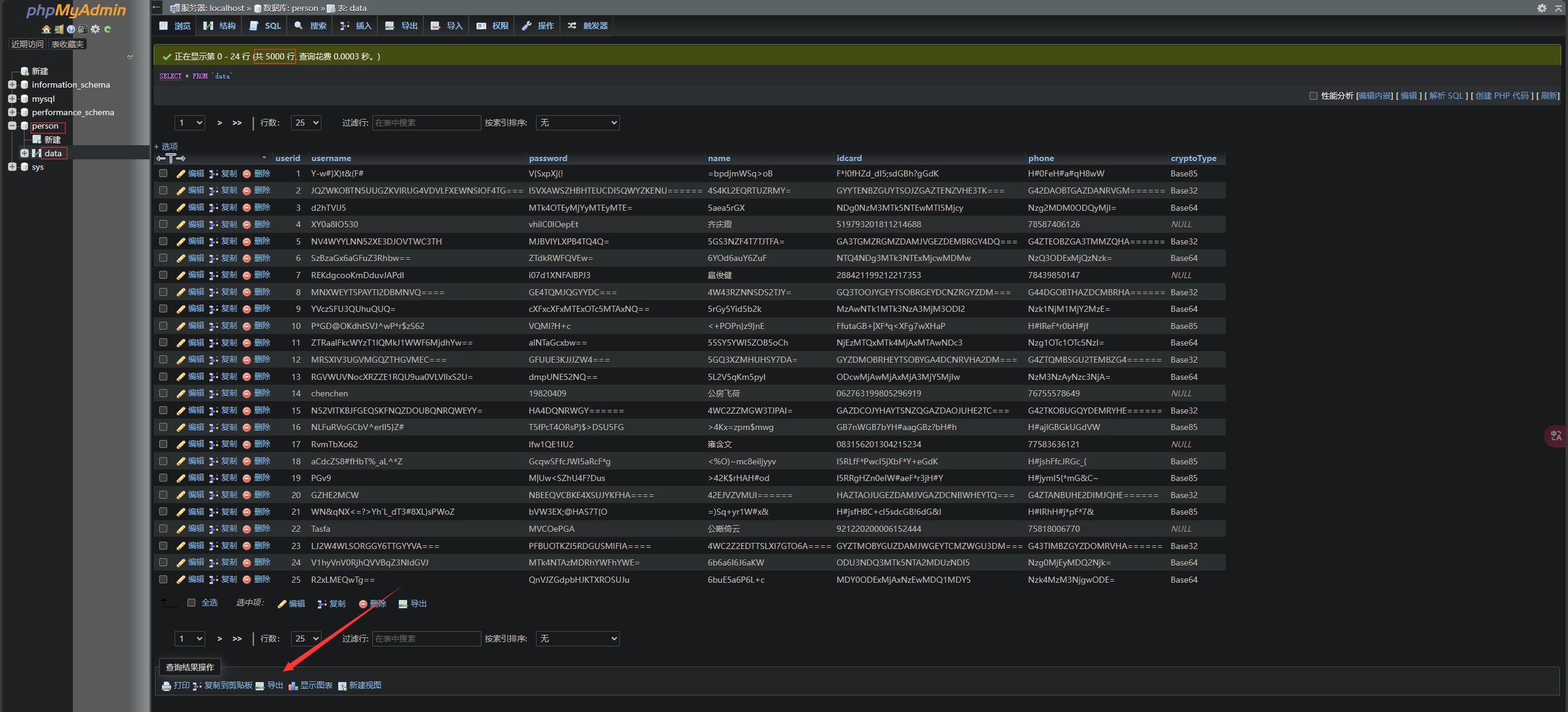
打开后发现有个person库中有个data表,总共5000条数据,导出为csv,其实题目名也能看出,使用不同的编码来解码,根据cryptoType字段中的编码来解码这一行中的除了userid所有数据即可
这么多数据量,可以尝试利用编写python批量解码
1 | import json |
得到正常数据后,查看题目附件还有个PDF文件

要求是这样的,那就根据规范文档再对数据进行脱敏处理,根据上传规范定义了CSV文件的列标题,删除cryptoType字段,最终脚本如下
1 | import json |
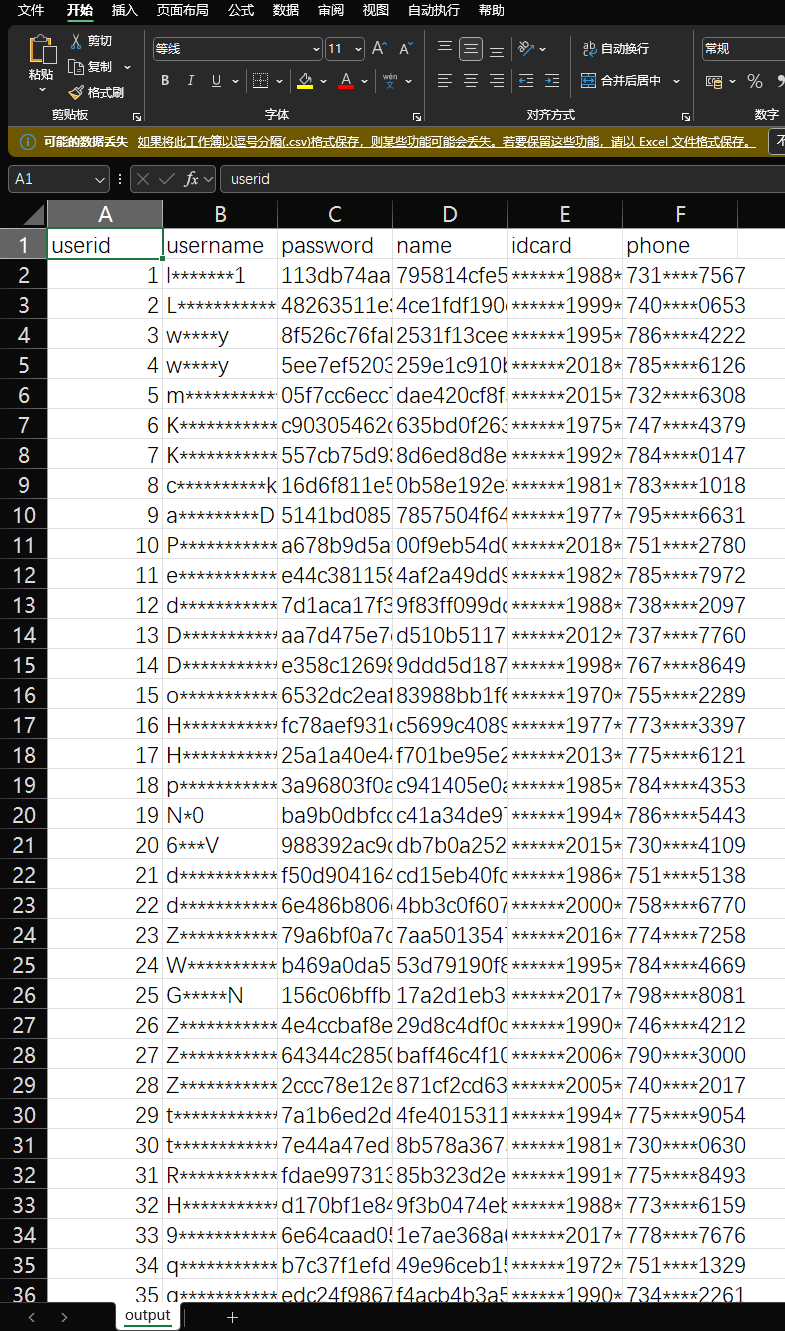
最后将output.csv文件上传即可获得flag